原文在这里。
由 Robert Findley and Alan Donovan 发布于 2023年9月13日
今年夏天初,Go团队发布了gopls的v0.12版本,这是Go语言的语言服务器,它进行了核心重写,使其能够适应更大的代码库。这是一项长达一年的努力的成果,我们很高兴分享我们的进展,并稍微谈一下新的架构以及它对gopls未来的意义。
自v0.12版本发布以来,我们已经对新设计进行了微调,重点是使交互式查询(如自动完成或查找引用)的速度与v0.11相比保持不变,尽管内存中保存的状态要少得多。如果您还没有尝试过,我们希望您会尝试一下:
$ go install golang.org/x/tools/gopls@latest
我们很想通过这份简短的调查了解您对它的使用体验。
减少内存占用和启动耗时
在深入了解详细信息之前,让我们先来看一下结果!下面的图表显示了GitHub上最受欢迎的28个Go存储库的启动时间和内存使用情况的变化。这些测量是在打开一个随机选择的Go文件并等待gopls完全加载其状态后进行的,由于我们假设初始索引会在多个编辑会话中分摊,所以我们是在第二次打开文件时进行这些测量的。
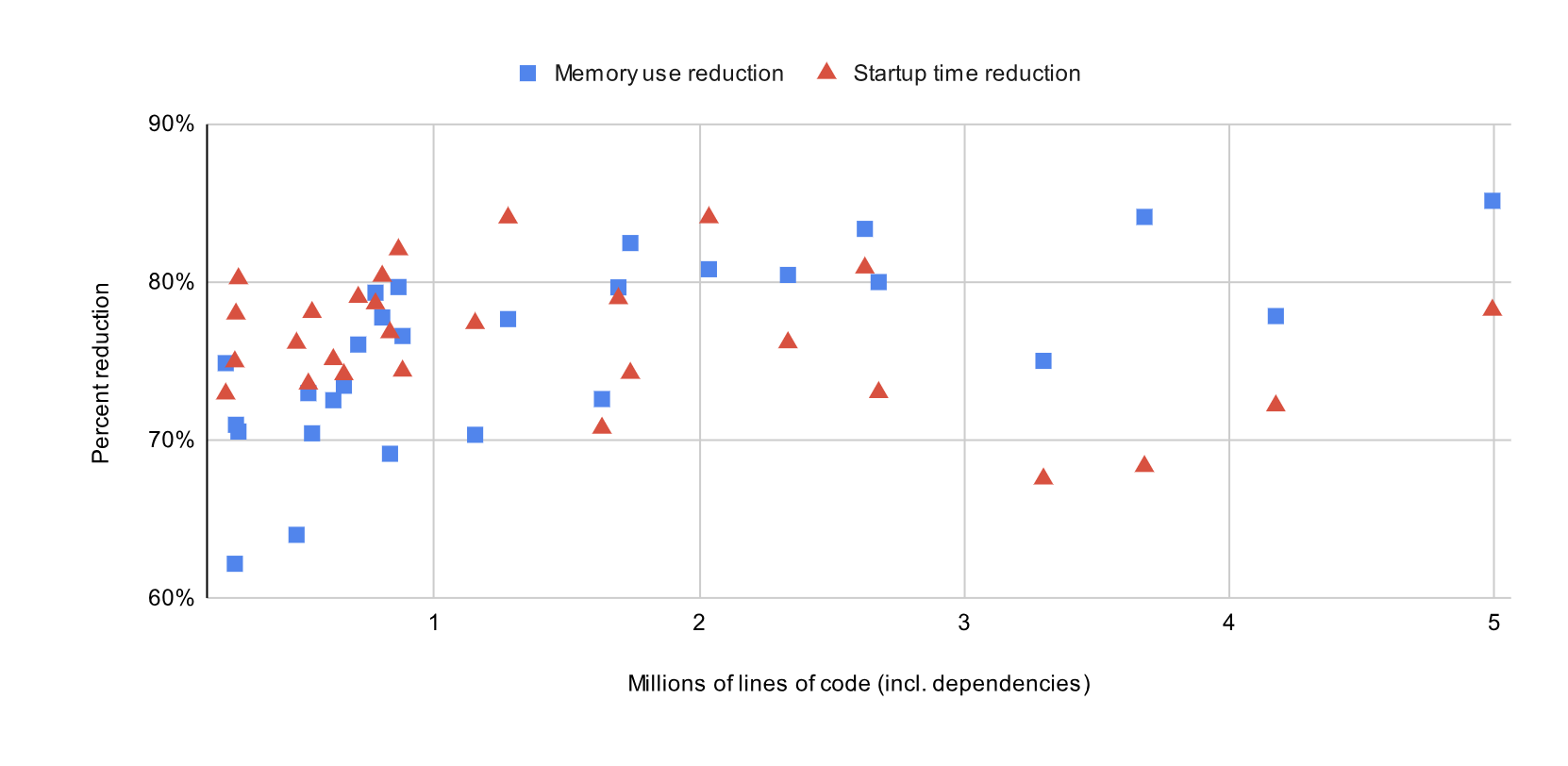
在这些存储库中,节省的平均值约为75%,但内存减少是非线性的:随着项目变得越来越大,内存使用的相对减少也会增加。我们将在下面更详细地解释这一点。
Gopls和不断发展的Go生态系统
Gopls提供了类似IDE的功能,如自动完成、格式化、交叉引用和重构等,适用于与语言无关的编辑器。自2018年开始,gopls已经整合了许多不同的命令行工具,如guru、gorename和goimports,成为了VS Code Go扩展以及许多其他编辑器和LSP插件的默认后端。也许你一直在使用gopls,而甚至不知道它的存在,这正是我们的目标!
五年前,gopls通过维护有状态的会话仅提供了性能的改进。而旧版命令行工具每次执行都必须从头开始,gopls可以保存中间结果以显著降低延迟。但所有这些状态都带来了一定的成本,随着时间的推移,我们越来越多地听到用户反馈,即gopls的高内存使用几乎难以忍受。
与此同时,Go生态系统不断增长,越来越多的代码被写入了更大的存储库。Go工作区允许开发人员同时处理多个模块,并且容器化开发将语言服务器放入了资源受限的环境中。代码库变得越来越大,开发环境变得越来越小。我们需要改变gopls的扩展方式,以跟上这一发展趋势。
重新审视gopls的编译器起源
在许多方面,gopls类似于一个编译器:它必须读取、解析、类型检查和分析Go源文件,为此它使用了Go标准库和golang.org/x/tools模块提供的许多编译器构建块。这些构建块使用了“符号编程”的技术:在运行编译器时,每个函数(如fmt.Println)都有一个单一的对象或“符号”代表。对于函数的任何引用都表示为指向其符号的指针。要测试两个引用是否指的是同一个符号,您不需要考虑名称。您只需比较指针。指针比字符串要小得多,指针比较非常便宜,因此符号是表示一个像程序这样复杂的结构的高效方式。
为了快速响应请求,gopls v0.11将所有这些符号都保存在内存中,就好像gopls一次性编译了整个程序。结果是内存占用量与正在编辑的源代码成比例,并且远远大于源文本(例如,类型化语法树通常比源文本大30倍!)。
独立编译
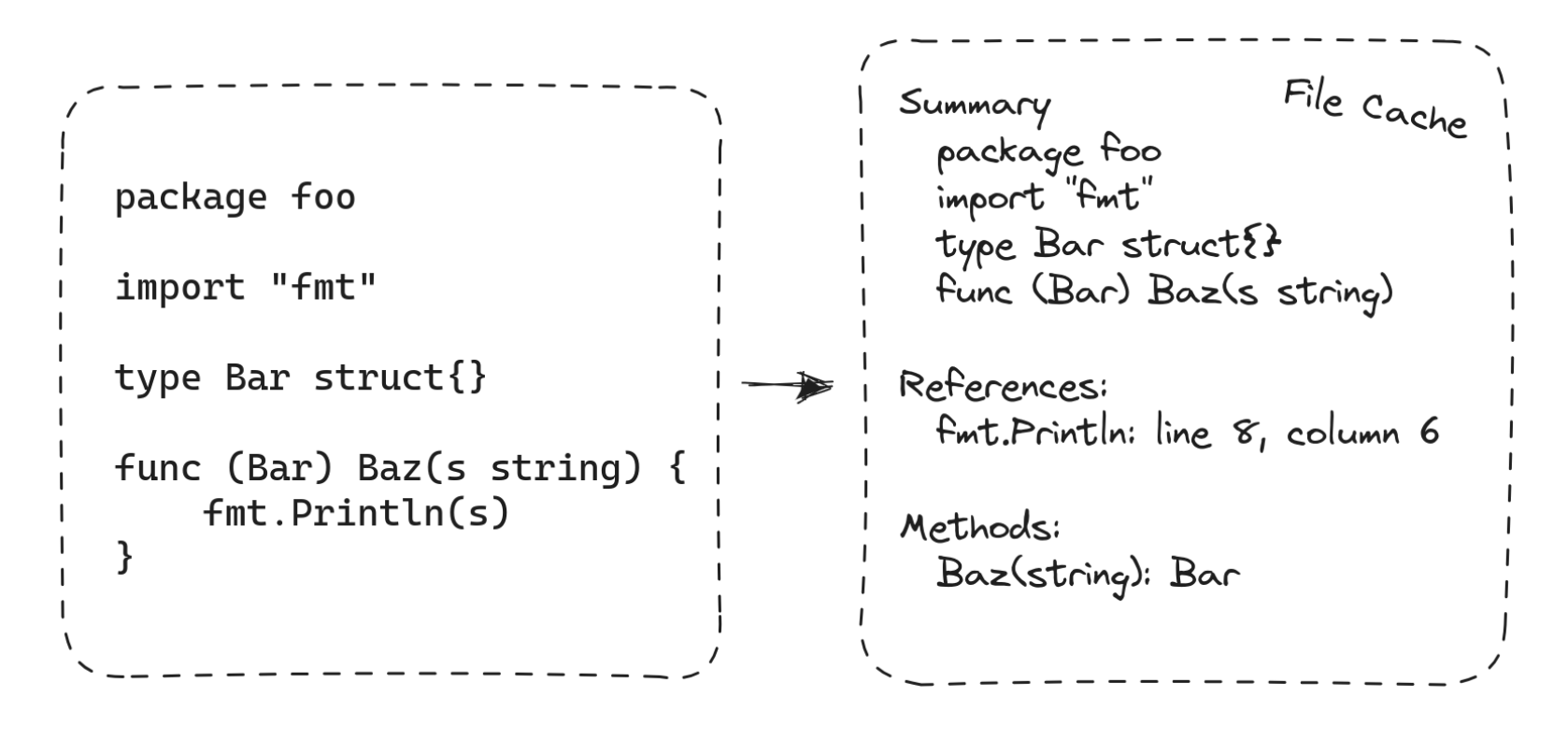
20世纪50年代,第一批编译器的设计者很快发现了单体编译的限制。他们的解决方案是将程序分为单元,并分别编译每个单元。独立编译使得可以将程序分成小块进行构建,即使程序无法全部放入内存也能构建完成。在Go中,单元是包(packages)。不同包的编译无法完全分开:当编译一个包P时,编译器仍然需要有关P导入的包提供了什么信息。为了安排这一点,Go构建系统在P本身之前编译了P导入的所有包,并且Go编译器编写了每个包的导出API的简洁摘要。P导入的包的摘要作为输入提供给P本身的编译。
Gopls v0.12将独立编译引入了gopls,重用了编译器使用的相同包摘要格式。这个想法很简单,但细节中有微妙之处。我们重写了以前检查表示整个程序的数据结构的每个算法,使其现在一次只处理一个包,并将每个包的结果保存到文件中,就像编译器发出对象代码一样。例如,查找对函数的所有引用曾经是在程序数据结构中搜索特定指针值的所有出现的情况一样容易。现在,当gopls处理每个包时,它必须构建并保存一个索引,将源代码中每个标识符的位置与它所引用的符号的名称关联起来。在查询时,gopls加载和搜索这些索引。其他全局查询,如“查找实现”,使用类似的技术。
与go build命令一样,gopls现在使用基于文件的缓存存储来记录从每个包计算的信息摘要,包括每个声明的类型、交叉引用的索引和每个类型的方法集。由于缓存在进程之间保持不变,您会注意到第二次在工作区启动gopls时,它变得更快地准备好提供服务,如果运行两个gopls实例,它们可以协同工作。
这个改变的结果是,gopls的内存使用量与打开的包数量及其直接导入相关。这就是为什么在上面的图表中我们观察到了次线性的扩展:随着存储库变得更大,任何一个打开的包所观察到的项目的比例变得更小。
失效的细粒度
当您在一个包中进行更改时,只需要重新编译导入该包的包,不论是直接还是间接导入。这个想法是自20世纪70年代的Make以来所有增量构建系统的基础,自gopls创立以来一直在使用。实际上,在支持LSP的编辑器中的每次按键都会启动一个增量构建!然而,在大型项目中,间接依赖关系会累积,使这些增量重建变得过于缓慢。事实证明,很多这些工作并不是绝对必要的,因为大多数更改,例如在现有函数中添加语句,不会影响导入摘要。
如果您在一个文件中进行小的更改,我们必须重新编译它的包,但如果更改不影响导入摘要,我们不必编译任何其他包。更改的效果被“剪枝”了。一个影响到导入摘要的更改需要重新编译直接导入该包的包,但大多数这种更改不会影响这些包的导入摘要,如果是这样,效果仍然被剪枝,避免了重新编译间接导入者。由于这种剪枝,很少有一个低级包中的更改需要重新编译所有间接依赖于该包的包。剪枝的增量重建使得工作量与每个更改的范围成正比。这不是一个新的想法:它由Vesta引入,并且也在go build中使用。
v0.12版本引入了类似的剪枝技术到gopls,更进一步实现了基于语法分析的更快的剪枝启发式。通过保持内存中的符号引用简化图,gopls可以快速确定包c中的更改是否可能通过一系列引用影响包a。

在上面的示例中,从a到c没有引用链,因此即使a间接依赖于c,a也不会受到c中更改的影响。
新的可能性
虽然我们对我们取得的性能改进感到满意,但我们也对几个gopls功能感到兴奋,因为现在gopls不再受内存限制。
第一个是强大的静态分析。以前,我们的静态分析驱动程序必须在gopls的内存表示的包上运行,因此无法分析依赖关系:这样做会引入太多的额外代码。去掉这个要求后,我们能够在gopls v0.12中包含一个新的分析驱动程序,该驱动程序分析所有依赖关系,从而提高了精度。例如,gopls现在会报告Printf格式错误,即使是您在fmt.Printf周围的用户定义包装器也是如此。值得注意的是,多年来,go vet一直提供了这种精度,但是gopls在每次编辑后实时进行此操作是不可能的。现在可以了。
第二个是更简单的工作区配置和更好的构建标签处理。这两个功能都意味着当您在计算机上打开任何Go文件时,gopls都会“做正确的事情”,但是在没有优化工作的情况下都是不可行的,因为(例如)每个构建配置都会增加内存占用!
赶快尝试吧
除了可扩展性和性能改进之外,我们还修复了许多已报告的错误,以及在转换期间提高测试覆盖率时发现的许多未报告的错误。
要安装最新的gopls:
$ go install golang.org/x/tools/gopls@latest
请尝试一下并填写调查问卷 - 如果遇到错误,请报告它,我们将进行修复。

声明:本作品采用署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)进行许可,使用时请注明出处。
Author: mengbin
blog: mengbin
Github: mengbin92
cnblogs: 恋水无意